
Beyond Linear Thought
Large language models have made huge strides through scaling - more parameters, deeper reasoning traces, longer contexts. But beneath this progress lies a fundamental limitation: most models still rely on a strictly linear mode of thinking. They generate a single stream of reasoning, token by token, that must carry the entire cognitive process forward without the ability to restructure or parallelize thought.
As tasks grow more complex and multi-layered, this linearity becomes a bottleneck. Small early errors propagate, uncertainty compounds, and models struggle to reconcile conflicting information within a single trajectory. Attempts to compensate with multiple samples only replicate the same structure rather than reimagining it.
The emerging field of asynchronous reasoning, highlighted in Microsoft’s recent AsyncThink research, introduces a different perspective. It moves beyond the idea of a model as a single-threaded mind and begins to treat it as a distributed cognitive system - one capable of decomposing problems, launching parallel lines of analysis, and synchronizing insights through explicit coordination.
This isn’t a minor optimization. It’s a redefinition of what it means for an AI system to think - and it has far-reaching implications for reliability, scalability, and intelligent system design.
Inside the Model
To understand what asynchronous reasoning actually changes, we need to look at the internal mechanics of how a large language model thinks. In the traditional paradigm, reasoning unfolds as a single, continuous chain of tokens - essentially one long stream of thought. Each step depends on the previous one, and the model has no ability to reorganize or restructure its thinking once the sequence is underway. It simply advances forward along the same path.
This linear structure imposes strict constraints. A single assumption made early in the chain carries through the entire reasoning process. When a problem involves multiple interacting components, all of them must be handled within one fragile sequence. And when uncertainty arises, the model has no built-in mechanism for branching into alternatives or recombining different lines of analysis before committing to a final answer.

Asynchronous reasoning introduces a different internal architecture. Instead of treating reasoning as a monologue, it treats it as a distributed system - a coordinated set of internal processes, each responsible for a distinct aspect of the problem. When the model identifies a point where the task can be decomposed, it initiates a Fork: a deliberate decision to split the reasoning path into parallel branches.
Each resulting worker operates in its own isolated context. These workers are not duplicated samples; they are intentionally created cognitive units focused on specific subproblems. One branch may examine assumptions, another may evaluate alternatives, while another explores edge cases or supporting evidence.
Once these branches have progressed, the model brings them back together in a structured Join operation. Here, the intermediate results are aligned, inconsistencies are resolved, and the global reasoning state is updated before the process continues. The result is not a single line of thought but a dynamic reasoning DAG - a directed graph of interconnected reasoning paths constructed and adjusted in real time.
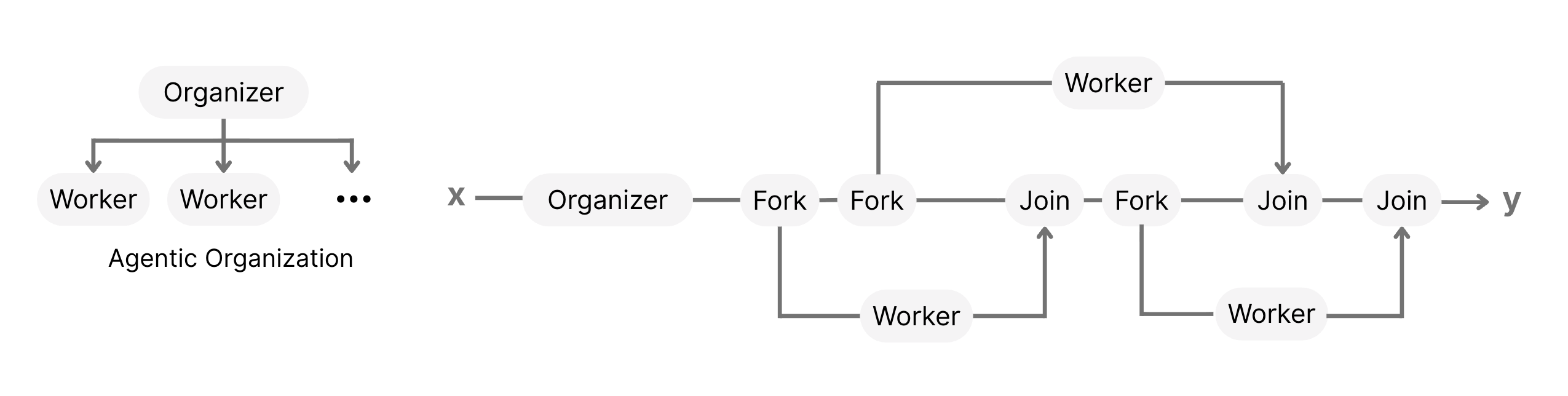
Through this architecture, the model develops the ability to manage the structure of its own thinking: deciding when to branch, when to converge, how to isolate reasoning threads, and how to synchronize them - all internally, without external orchestration
Why It Matters
Once reasoning inside the model becomes distributed rather than linear, the practical implications shift dramatically. For enterprises, the value of this change has less to do with the novelty of the architecture and everything to do with how it affects reliability, scalability, and operational stability.
Most issues that limit real-world AI deployments today stem from the fragility of single-trajectory reasoning. A model’s output can swing unpredictably based on early token choices. Complex tasks force long chains that increase latency. Multiple-sample approaches inflate costs without improving structural integrity. And because reasoning is opaque, organizations have little visibility into why the system arrived at a particular conclusion.
Asynchronous reasoning changes this landscape by altering the environment in which these problems occur. When a model can structure its own reasoning, separating concerns, exploring alternatives, synthesizing perspectives, the external behavior becomes more stable and more aligned with enterprise needs.
Three shifts stand out:
1. More predictable and reliable behavior
Distributed reasoning reduces sensitivity to early-token randomness and single-thread failure cascades. For organizations, this translates into more consistent outputs across repeated runs and more dependable performance in high-stakes workflows.
2. Smarter allocation of computational effort
Instead of compensating for task complexity with longer chains or multiple samples, the model can internally allocate effort where uncertainty actually resides. This makes advanced reasoning more economically viable and enables scale without runaway inference costs.
3. A foundation for transparency and governance
Forks, joins, and intermediate reasoning states create a natural structure that can be inspected, monitored, and audited. For regulated industries, this is not a bonus - it is essential for validating decisions, addressing compliance requirements, and ensuring system accountability.
The shift, in other words, is not only architectural. It reshapes the operational properties of AI systems, making them more suitable for integration into environments where consistency, cost discipline, and governance are non-negotiable.
The Hybrid Future
While asynchronous reasoning reshapes how a model organizes its thoughts internally, real-world AI systems depend just as much on what happens around the model. Enterprise deployments rarely involve a single model producing an answer in isolation. They involve workflows, tools, APIs, retrieval systems, safety layers, and human oversight - all interacting as part of a larger decision-making process.
Traditional LLMs introduce friction into this landscape. Their linear, opaque reasoning forces orchestration frameworks to work around unpredictable behavior, variable latency, and the lack of interpretable intermediate states. The system must compensate for constraints the model cannot address. A model capable of structuring its own reasoning changes that dynamic.
When internal cognition becomes more modular, more deliberate, and more synchronizable, it aligns far more naturally with the architectures that govern modern AI systems. Multi-agent frameworks, tool-using agents, and retrieval-augmented pipelines can interact with a model whose internal processes themselves have structure - rather than a model that produces one undifferentiated stream of tokens.
This opens the door to a hybrid architecture, where:
• the model handles the internal organization of thought, and
• the surrounding system handles workflow, context, and domain logic.
Instead of a monolithic black box at the center of the stack, the model becomes a reasoning component with shape - something other agents can query, coordinate with, and build on. Verification agents can inspect intermediate branches, planning agents can incorporate structured reasoning output, and domain-specific agents can request targeted branches rather than generic answers.
The result is smoother alignment between cognition and orchestration. Workflows become less brittle. Tool use becomes more purposeful. System-level agents no längre behöver “fight” the model’s linearity - they can collaborate with a reasoning process that is already organized internally.
Connecting the Dots
What stands out, when stepping back from the technical details, is how naturally this new model-level structure echoes ideas that have been developing on the systems side for some time. Before asynchronous reasoning was formalized, many applied AI teams were already exploring how to move beyond monolithic, single-trajectory cognition — experimenting with architectures that distribute reasoning across multiple coordinated components.
At Predli, this exploration led us to frameworks like H-MAC, a hierarchical multi-agent architecture built around structured decomposition and collaboration. The goal has always been clear: give systems the ability to break down complex tasks, handle specialized subtasks, synchronize intermediate reasoning, and maintain global coherence in a principled way.
What AsyncThink illustrates is that these patterns are now beginning to appear inside the model itself. The same architectural principles - decomposition, parallelism, verification, structured communication - are becoming native to model-level reasoning. It’s a strong signal that the field as a whole is gravitating toward a shared intuition: scalable intelligence emerges from organization, not just computation.
Internally, models are learning to structure their own thinking into parallel reasoning graphs. Externally, agent systems coordinate workflows, manage tools, and enforce domain-specific constraints. Together, these layers form adaptive cognitive ecosystems capable of handling the complexity and ambiguity of real-world enterprise environments.
In that sense, asynchronous reasoning doesn’t replace existing architectures - it complements them. It reinforces a direction that many groups, including ours, have found both natural and necessary as AI systems mature.
